
Multimodal Miscues

I'm preparing for my first speaking gig of 2026. The topic shouldn't surprise anyone these days: AI with a dash of citizen development.
As I do with all my talks, I bring my receipts in the form of data. Lots of data. To that end, why not enlist AI to help me generate compelling visualizations?
It's not a difficult ask. Standalone AI image generators have existed since 1973. These days, you need neither a dedicated tool to produce computer-generated JPG and PNG files nor a design program like Canva. Put differently, mainstream AI chatbots are multimodal. As you'll see in this post, they continue to make plenty of baffling non-text mistakes.
Prompting Gemini
I used Claude's deep research feature to generate some recent surveys and studies on AI in the workplace. I threw the results into Notion, took a screenshot of one promising survey, and then crossed over to Gemini. Here's my initial prompt:

Here's its initial response:
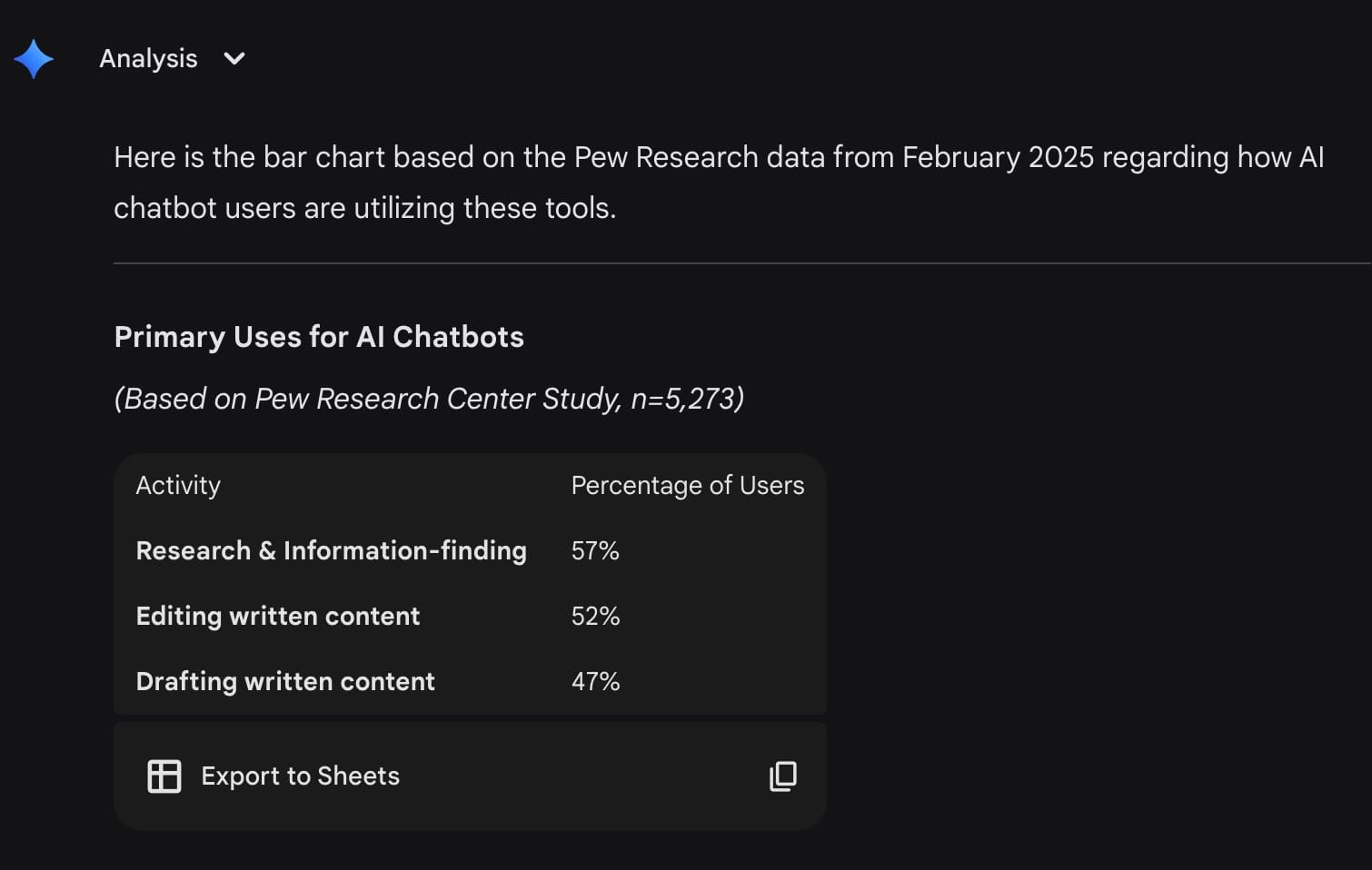
That's the data in a structured format. It's a good start, but Gemini failed to produce the requested chart. I responded with the following prompt.
And Gemini then gave me the abomination below:
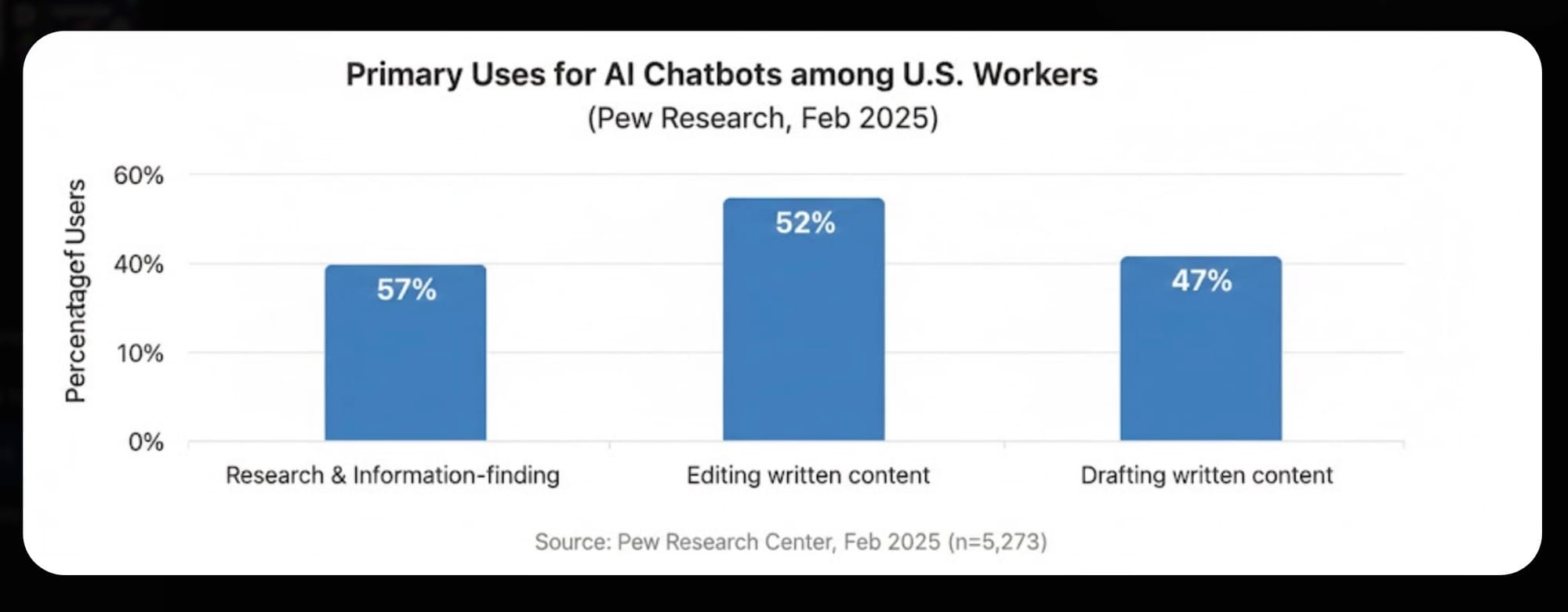
See a problem?
Sometimes, it's just quicker to pretend that Gemini, Perplexity, and ChatGPT don't exist.
I had to go old school.
AI as a Designer
For a recent post's featured image, I gave Google's much-hyped Nano Banana the following prompt:
Nano Banana required four attempts to return something passable. Pictures of decapitated celebrities aren't my jam.




The Fourth Time Was a Charm | Image Sources: Google Nano Banana

The AI Paradox Is Alive and Well
So smart one minute and so dumb the next. Expect plenty of hallucinations—and not just in text-based responses.
Such is life in the age of AI. Sometimes, it's just quicker to pretend that Gemini, Perplexity, and ChatGPT don't exist.
Feedback
What say you?






Member discussion