 PHIL SIMON
PHIL SIMON
This is the first post in a three-part series.
I’m old enough to remember when IT was largely seen as the gatekeeper of corporate information. When I first entered the corporate world in 1997, I had to request access to data from the IT department. Sure, IT provided limited access to certain datasets, but anything other than that required an often-arduous back-and-forth with techies charged with guarding corporate information. In other words, if employees in HR, marketing, sales, and the like wanted data back then, there was simply no way to avoid dealing with IT. Fifteen years ago, the vast majority of all corporate data was stored on-premise. Cloud computing existed but it was nowhere near as prevalent as it is today. Despite the proliferation of modern cloud computing, the “IT as gatekeeper of all information” mind-set pervades many hidebound organizations. More progressive ones, though, have evolved and enabled non-technical employees to effectively fish for themselves. No longer do everyday (read: non-technical) employees need to formally request access to internal datasets and wait days or weeks for approval.
Google, Big Data, and the Role of Traditional IT
Exhibit A: Gartner is regarded as the world’s leading information technology research and advisory company. It has added self-service business intelligence to its IT glossary. Gartner defines SSBI as “end users designing and deploying their own reports and analyses within an approved and supported architecture and tools portfolio.”
Almost every employee is also a consumer.
The rise of employee self-service isn’t too difficult to understand. Almost every employee is also a consumer. For a long time now, we have been very comfortable trying to discover what we want and need on our own. Google processes an astonishing 40,000 searches per second. Whether or not IT should control all corporate data remains a fundamental philosophical question in many organizations. I’d argue that it’s a moot one anyway. The arrival of Big Data means that IT cannot even begin to “manage” everything anyway. Think about the explosion of data sources: Open Data, Linked Data, data from social sources (read: Facebook, LinkedIn, Twitter, Pinterest, etc.), and others. Yes, data storage costs have dropped by orders of magnitude (see Kryder’s Law).
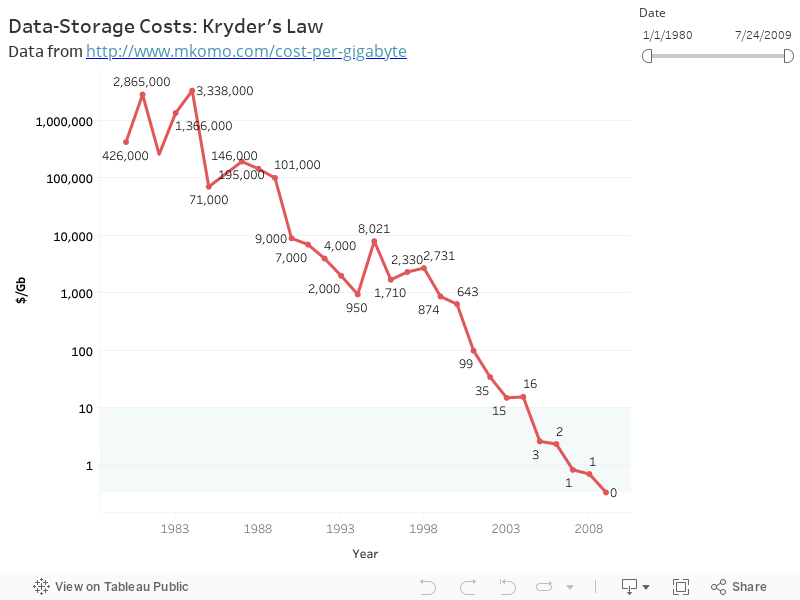
At the same time, though, let’s not confuse “cheaper” with “cheap.” It’s apocryphal to claim that data storage costs are always insignificant, not to mention that related employee salaries add up.
Simon Says
Fortunately, there’s relief. New data-discovery and -analysis applications have arrived. As a whole, they have dramatically simplified how employees access, mesh, and report on organizational data. Today, executives, non-technical “analysts”, and independent software vendors can largely meet their own data needs sans the involvement and imprimatur of the IT department.
In my next post in this series, I’ll explore the benefits of embracing employee self-service.
![]() While the words and opinions in this post are my own, Progress Software has compensated me to write it.
While the words and opinions in this post are my own, Progress Software has compensated me to write it.


0 Comments